
The science of producing predictions about what content people want to see next is based on lots of data. For example, things that are particularly interesting to a recommendation engine are items that have been seen in conjunction with other items, things downloaded in the same session, and content browsed before and after a purchase, to name a few. These relationships are known to the engine as interesting, because algorithms have been designed to look for them.
Predictive algorithms look for relationships
There are many algorithmic methods (math-based instructions for solving a problem) to generate recommendations, including:
- Item Hierarchy (You bought a set of golf clubs, therefore you also need golf balls)
- Attribute Based (You like action-packed, non-violent, science-fiction movies with a strong female hero)
- Collaborative Filtering with User-User Similarity (People like you who bought opinionated t-shirts also bought fashionable combat boots)
- Content-Based Filtering with Item-Item Similarity (“Kill Bill” is similar to “12 Monkeys” therefore you will like watching it)
- Social+Interest Graph Based (your friends like Angry Birds so you’ll like Angry Birds)
- Model Based (pattern recognition for implicit behaviors combined with machine learning)
The topic of predictive algorithms can get deep pretty fast, but having some technical knowledge is the basis for smarter business decisions and profitable investments, so let’s break it down into different practical business cases.
Collaborative filtering
Collaborative filtering, also known as behavioral clustering, is a method that builds a data model based on a person’s past behavior, as well as similar historical activities by other people. For example, items previously browsed, searched, clicked, “liked,” downloaded, purchased, and preference ratings given to those items.
A principle behind collaborative filtering assumes that consumers are likely to enjoy items similar to those they’ve already purchased or downloaded, etc. It then follows that they will also demonstrate similar patterns and take actions consistent with the people that they are “the most like.”

Let’s consider a simple example of collaborative filtering based on three visitors to an e-commerce shop:
- Jake got a beach ball and sunglasses
- Funmi got a bikini
- Nick got a beach ball
- What else would Nick want?
The next email that Nick gets from this store will include a pair of sunglasses as a recommendation. Based on the data available, Nick looks more similar to Jake than he does to Funmi. The Recommendation Engine does not need to know that Funmi is a girl and the other two are boys, the data patterns actually reveal the item that is best.
It looks pretty simple, so you might be wondering why a predictive and automated system is needed to produce the answer for smart marketers? This example is super basic for the purposes of conveying the logic. Adding just one more person-scenario significantly increases complexity:
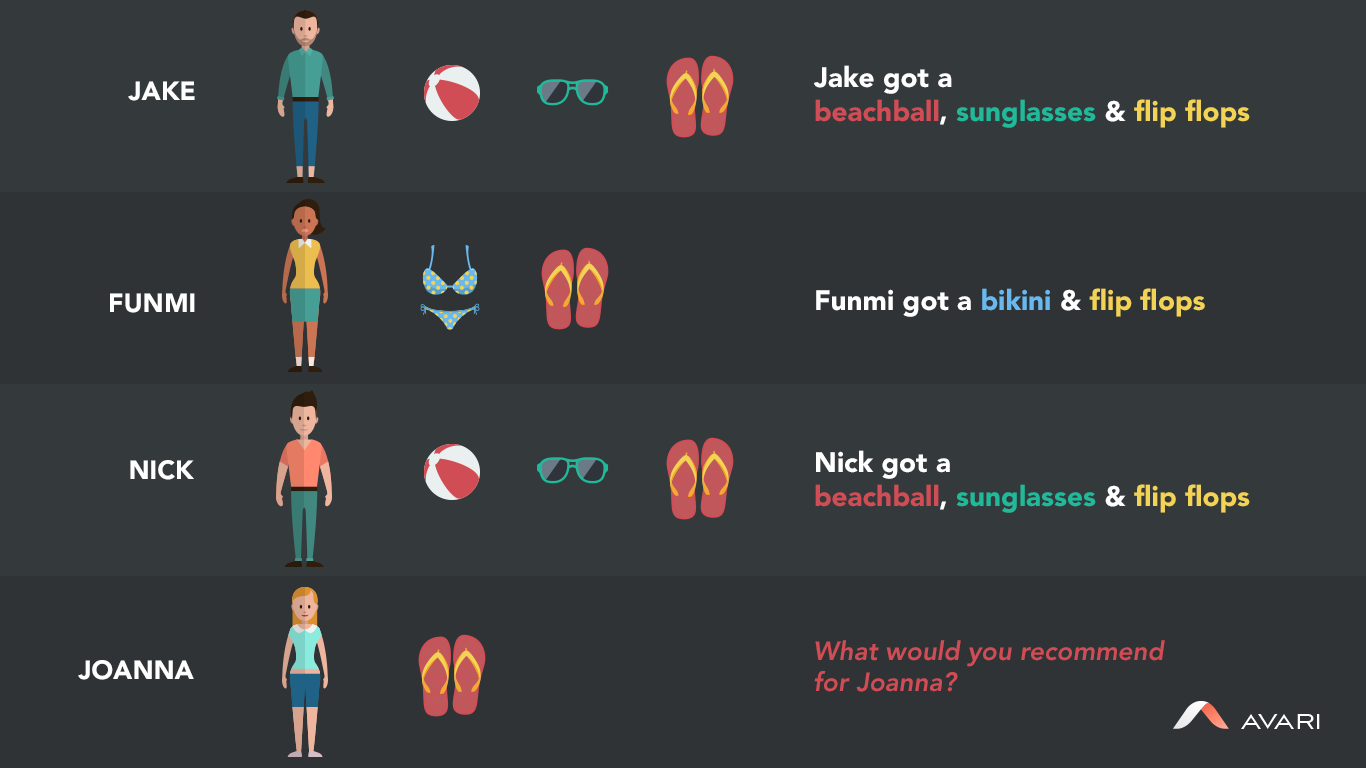
We could guess that the next email Joanna gets will contain a bikini, because she and Funmi are both female and the patterns in the data may pick up on that. But it could also be that Joanna is more similar to Jake because they’re both from Australia, and according to the data from dozens of Australians that shop at the store, everyone Down Under wears green shades.
There can be infinitely more products in the store that have relationships that are relevant, and infinitely more customers and website visitors with patterns to take into account. Furthermore, this example only looks at an order when in reality much more online behavior is also quite important. Finally, all of this needs to be assessed and updated continuously and in real-time in order to be most relevant.
Collaborative filtering is an algorithmic method that can reverse engineer and understand your customers down to the individual level. The patterns in behavior of visitors to your website are a rich source of information about who your customers are and what they value from you. That’s collaborative filtering in a nutshell.
Content-based filtering
Another method, content-based filtering, also known as product clustering, is a method that uses a set of specific characteristics related to an item (tags, categories, pricing, and other less defined attributes) in order to identify and recommend additional items with similar properties.
For example: items categorized as male may have a higher likelihood of being recommended with other items categorized as male; clothes tagged as red will be more likely to show up with other red items; items priced at a premium will be grouped with other premium products.
Again, it sounds simple in theory but the complexity is in the scaling. Content-based filtering is especially important to ensure that the data model takes a big-picture view of your entire product or content “catalog.”
Both the collaborative filtering and content-based filtering methods have been around for a while, but they remain the most advanced ways to produce recommendations — and the real magic happens when the two are put together.
Hybrid Recommendation Engines offer better personalization
A good Recommendation Engine strives to provide as much personalization as possible. For example, any mix of items on a website should be able to be assembled as a set for one individual. To get closer to achieving this capability, “hybrids” combine multiple algorithmic methods.

